
For centuries, society relied almost exclusively on paper for its record-keeping needs. Then, computers came along and changed how we store information, making it much easier to access. Digitization meant that even an obscure bit of trivia from an out-of-print encyclopedia was just a quick Google search away.
While it’s easy to take that sort of convenience for granted in 2024, we can enjoy it because of technology that has been years in the making: text recognition.
Text recognition is a powerful tool — one that can bridge the gap between paper-based and digital knowledge systems. The technical term for text recognition is optical character recognition (OCR), which is a valuable technology that can extract data from printed or handwritten documents and convert it into an editable digital text document.
In layman’s terms, OCR is used to create digital versions of existing scanned documents.
As the world becomes more reliant on digital means of storing and accessing information, OCR software as a whole, particularly text recognition, will become extremely important in converting old information archives into digital databases. This article will explore the role of text recognition in modern applications.
Text recognition is a tool for the future
OCR is a fast process that quickly converts documents into digital text files. The advantage of having a digital form to edit with word processing software like Microsoft Word or Google Docs is that document management becomes much simpler.
But it has taken decades to get here.
Text recognition got its start 50 years ago, in 1974. American computer scientist Raymond Kurzweil invented a reading machine that could recognize text in every conceivable printed font at the time. It was meant to serve as a text-to-speech processor for blind and visually impaired readers. However, the technology had the potential to transform the way document management worked, and OCR began to gather steam in the coming decades as the world transitioned from paper to computers.
Today, there are various forms of OCR software in use. The OCR market is growing as digitization becomes inevitable for any business in the modern environment. In 2023, the global OCR market size was valued at $12.56 billion and is predicted to grow at a compound annual growth rate of 14.8% until 2030.
Understanding how OCR technology works and how to apply it effectively is essential for a business looking to succeed in the modern digital landscape.
How OCR works
Ever since its inception, OCR technology has relied on a combination of hardware and software. The hardware component is a scanner that converts physical documents into an image. However, though the image contains text, that text isn’t readable for a computer. That means manual methods are the only way to analyze or edit the document. It’s not a very convenient solution.
That’s where the software component of OCR technology comes into play. It transforms scanned documents into machine-readable PDFs that can be searched, edited, or modified like any other text file on the computer. There are multiple steps behind how OCR software converts documents to text files, which we will examine below.
Step 1: Image acquisition
The scanned image is converted to binary, black-and-white data. When the OCR software scans this binary data, it reads dark areas as text and light areas as the background.
Step 2: Pre-processing
The next step is preparing the image so the computer can read it. The OCR software accomplishes this by fixing the alignment, clearing up digital image spots, and identifying the scripts used if the document is in multiple languages.
Step 3: Text recognition
This is where the magic happens. The OCR software reads the prepared image to capture the text data it contains. There are two common algorithms used by most OCR software.
-
Pattern matching: Most OCR software has a preloaded character glyphs and fonts database. The algorithm isolates individual character glyphs and matches them against stored glyphs in the database. Pattern matching can be limited by the number of fonts stored in its database.
-
Feature extraction: The OCR software is trained to identify specific features, such as angled lines, curves, or intersecting lines, which it then uses to recognize individual characters.
Next-generation OCR software also employs emerging technology like artificial intelligence (AI), machine learning (ML), and neural networks to mimic how the human brain recognizes text and converts data from scanned documents.
Step 4: Post-processing
Once the text recognition process is complete using either algorithm, the OCR software converts the identified characters into ASCII (American Standard Code for Information Interchange) code that computers can read for further manipulation.
The universal benefits of OCR
Text recognition is a technological tool with almost universal applications. It can be used for any language or script and is suitable for digitization projects at both small and large scales. This is because the benefits of OCR add value in nearly every scenario.
Every knowledge system containing physical documents could benefit from using OCR technology, even if they aren’t pursuing complete digitization. That’s because OCR makes it convenient to search through scanned text documents. It also boosts operational efficiency, allowing users to manipulate documents in new ways, such as compressing the files, editing the contents, or copying the data to new files.
OCR technology is superior to physical documents because it:
-
saves time,
-
reduces the likelihood of human error,
-
digitizes documents with minimum effort.
These benefits make OCR a valuable tool for organizations and individual users alike.
Benefits for businesses
Every business needs to invest in text recognition software if they want to enjoy the following advantages:
-
Streamlined data entry: Companies can use OCR technology to automate data extraction from images or documents. This accelerates workflows, freeing up employees from the manual effort of document routing and content processing.
-
Simplified record digitization: In a modern world, content digitization is an absolute must if a company wants to remain relevant. With OCR, data capture and document management become automated, bringing effective digitization within reach.
-
Security compliance: Physical documents can be accessed by anyone who knows where they are stored. Digital documents can be protected using passwords and encryption. This makes OCR extremely useful in scenarios where sensitive data and private information need to be stored.
Benefits for users
Text recognition tools add value for individual users in the following ways:
-
Improves user experiences: Once text data is converted to a computer-readable format, users can access many features that make the data more convenient to work with. Search functions and other interactive features are examples of how OCR improves user experiences.
-
Promotes accessibility: True to its origins as a tool to help blind people read, OCR technology continues to promote accessibility. This is made possible through applications to interpret and communicate information to users with different needs in different languages, thereby increasing the reach and usability of the data.
Real-world use cases of text recognition at work
Many industries have realized the potential of OCR technology in transforming their document management systems. Here are a few examples of how text recognition software is achieving phenomenal results in modern, real-world applications.
Banking
Banks can quickly and conveniently extract the necessary information from customer-provided identification documents using OCR. Text recognition has also digitized, and thereby optimized, check processing workflows.
Healthcare
Hospitals and other medical institutions handle large amounts of sensitive and confidential patient information. OCR technology enables healthcare providers to easily digitize lab reports, examination results, and health records for secure record-keeping purposes.
Education
Thanks to OCR, students will no longer have to constantly flip through the pages of a textbook. Text recognition lets students edit text to help with note-taking, highlighting portions of text, and placing bookmarks. Students with learning disabilities like dyslexia can also benefit from OCR’s text-to-speech functions while studying.
Many other industries have also embraced the convenience of OCR, including tourism, logistics, legal, and retail.
AI and ML: Text recognition and OCR’s new frontier
The new generation of OCR software is going even beyond its original function of text recognition. Thanks to ML algorithms, OCR technology can detect images, such as brand logos, on advertising material or product packaging. Object recognition, an offshoot of OCR, is used in self-driving vehicles to identify obstacles on the road.
Even the original field of text recognition is being transformed by AI. Advancements in AI technology, such as natural language processing (NLP) and sentiment analysis, mean that AI-enhanced OCR software will soon be able to read and analyze text data efficiently after digitizing it.
Innovation in text recognition has led to the development of software that doesn’t just recognize text data but effectively understands it. AI can analyze a text document and highlight its key topics and context. This deeper insight into text analytics improves their accuracy, helping businesses improve their processes and workflows based on customer feedback (and other sources of text data).
How OCR improves customer feedback analysis
One area where AI’s effectiveness at extracting accurate insights from text data has been proven is customer service analytics.
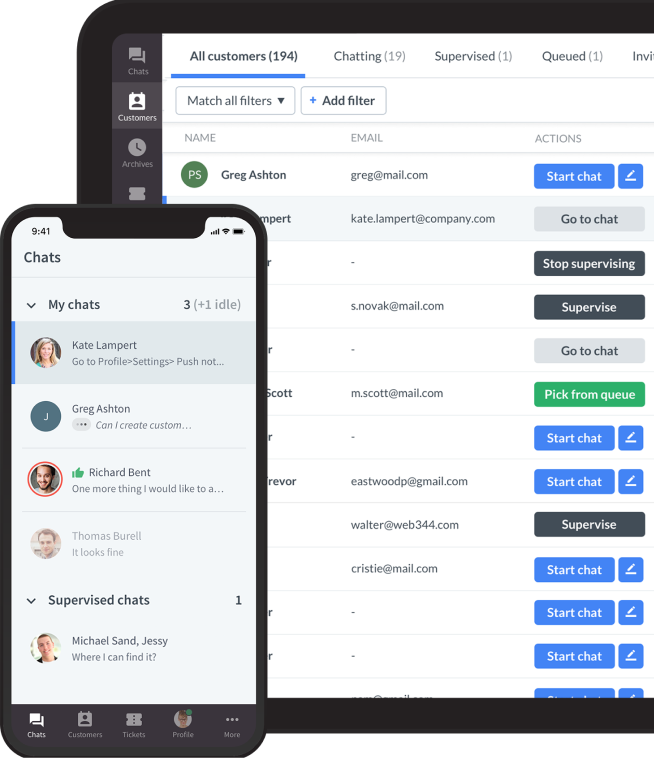
LiveChat is a chat app that provides a central hub for all customer service conversations. AI software can analyze all the text data from those chats to detect common problems, predict future issues, and suggest likely solutions.
Using OCR to digitize scanned documents like customer feedback forms increases the amount of text data the AI can access, improving its accuracy and delivering better results.

Get a glimpse into the future of business communication with digital natives.
Get the FREE report